嵌入模型
此概念概述著重於基於文本的嵌入模型。
嵌入模型也可以是多模態,但 LangChain 目前不支援此類模型。
想像一下,能夠以單一、精簡的表示形式捕捉任何文本的精髓——一條推文、文件或書籍。這就是嵌入模型的力量,它位於許多檢索系統的核心。嵌入模型將人類語言轉換為機器可以理解並快速準確地比較的格式。這些模型將文本作為輸入,並生成固定長度的數字陣列,即文本語義含義的數字指紋。嵌入使搜尋系統不僅可以基於關鍵字匹配,還可以基於語義理解來查找相關文件。
主要概念
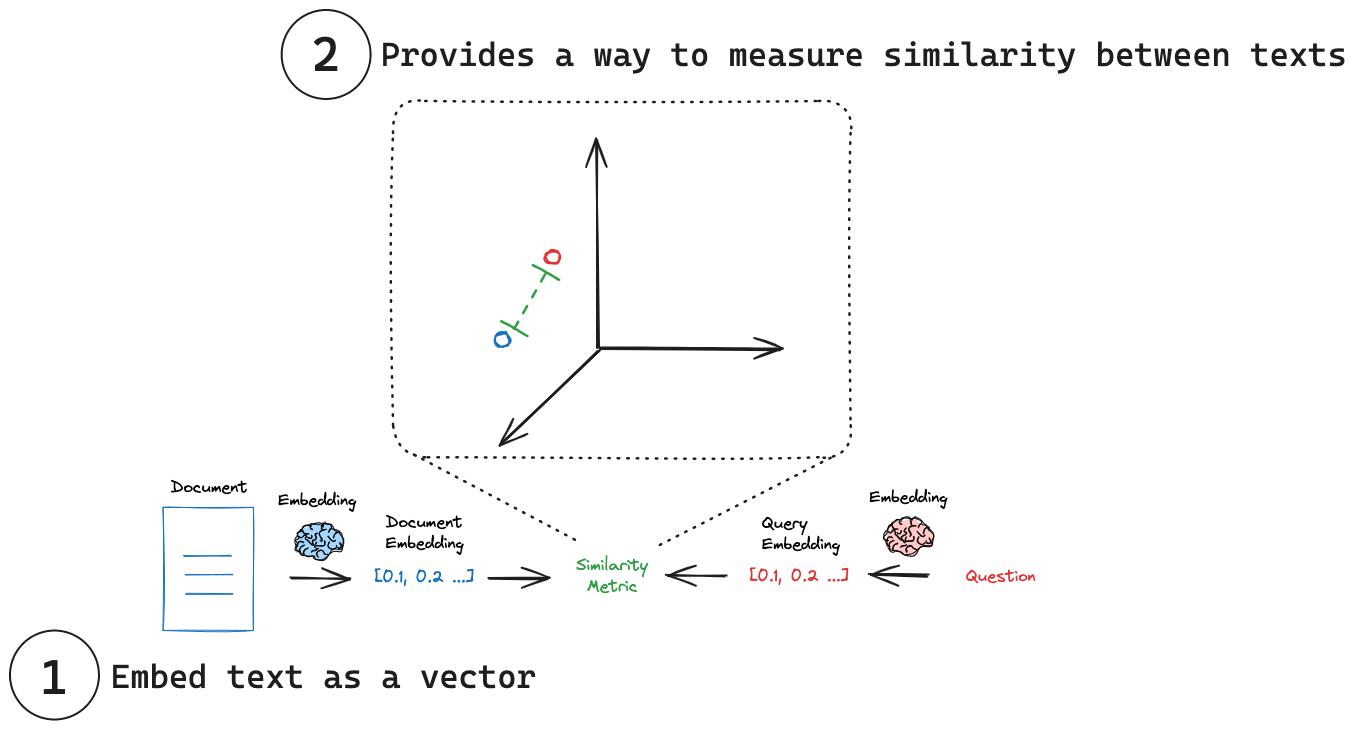
(1) 將文本嵌入為向量:嵌入將文本轉換為數值向量表示。
(2) 測量相似度:可以使用簡單的數學運算來比較嵌入向量。
嵌入
歷史背景
多年來,嵌入模型的格局發生了顯著的演變。2018 年,Google 推出了 BERT(Bidirectional Encoder Representations from Transformers,雙向編碼器轉換器表示法),這是一個關鍵時刻。BERT 應用轉換器模型將文本嵌入為簡單的向量表示,從而在各種 NLP 任務中實現了前所未有的效能。然而,BERT 並未針對有效生成句子嵌入進行優化。這種限制促使了 SBERT(Sentence-BERT,句子 BERT) 的創建,它調整了 BERT 架構以生成語義豐富的句子嵌入,可以通過餘弦相似度等相似度指標輕鬆比較,大大降低了查找相似句子等任務的計算開銷。如今,嵌入模型生態系統非常多樣化,眾多供應商提供自己的實作。為了應對這種多樣性,研究人員和從業者經常求助於大規模文本嵌入基準 (MTEB) 此處 等基準進行客觀比較。
- 請參閱 開創性的 BERT 論文。
- 請參閱 Cameron Wolfe 對嵌入模型的 精彩評論。
- 請參閱 大規模文本嵌入基準 (MTEB) 排行榜,以獲得嵌入模型的全面概述。
介面
LangChain 為使用它們提供了一個通用介面,為常見操作提供標準方法。此通用介面透過兩種核心方法簡化了與各種嵌入供應商的互動
embed_documents:用於嵌入多個文本(文件)embed_query:用於嵌入單個文本(查詢)
這種區別很重要,因為某些供應商對文件(要搜尋的對象)與查詢(搜尋輸入本身)採用不同的嵌入策略。為了說明,以下是使用 LangChain 的 .embed_documents 方法嵌入字串列表的實際範例
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
len(embeddings), len(embeddings[0])
(5, 1536)
為了方便起見,您也可以使用 embed_query 方法嵌入單個文本
query_embedding = embeddings_model.embed_query("What is the meaning of life?")
- 請參閱 LangChain 嵌入模型整合 的完整列表。
- 請參閱這些關於 如何使用指南,以了解如何使用嵌入模型。
整合
LangChain 提供了許多嵌入模型整合,您可以在嵌入模型整合頁面上找到。
測量相似度
每個嵌入本質上都是一組座標,通常在高維空間中。在這個空間中,每個點(嵌入)的位置反映了其對應文本的含義。就像在詞庫中相似的詞可能彼此靠近一樣,相似的概念最終在這個嵌入空間中彼此靠近。這允許不同文本片段之間進行直觀的比較。透過將文本簡化為這些數值表示,我們可以運用簡單的數學運算來快速測量兩個文本片段的相似程度,而無需考慮其原始長度或結構。一些常見的相似度指標包括
- 餘弦相似度:測量兩個向量之間角度的餘弦值。
- 歐幾里得距離:測量兩點之間的直線距離。
- 點積:測量一個向量在另一個向量上的投影。
相似度指標的選擇應根據模型選擇。例如,OpenAI 建議將餘弦相似度用於其嵌入,這可以輕鬆實現
import numpy as np
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
return dot_product / (norm_vec1 * norm_vec2)
similarity = cosine_similarity(query_result, document_result)
print("Cosine Similarity:", similarity)
- 請參閱 Simon Willison 關於嵌入和相似度指標的精采部落格文章和影片。
- 請參閱 Google 關於嵌入相似度指標的此文件。
- 請參閱 Pinecone 關於相似度指標的部落格文章。
- 請參閱 OpenAI 關於 OpenAI 嵌入應使用哪種相似度指標的常見問題解答。