檢索
這裡回顧的一些概念利用模型來生成查詢(例如,用於 SQL 或圖形資料庫)。這樣做存在內在風險。請確保您的資料庫連線權限已盡可能縮小範圍,以滿足您的應用程式需求。這將減輕(但不能消除)構建能夠查詢資料庫的模型驅動系統的風險。有關一般安全最佳實踐的更多資訊,請參閱我們的安全性指南。
概述
檢索系統是許多 AI 應用程式的基礎,可有效率地從大型資料集中識別相關資訊。這些系統適用於各種資料格式
- 非結構化文字(例如,文件)通常儲存在向量儲存或詞彙搜尋索引中。
- 結構化資料通常儲存在具有定義綱要的關聯式或圖形資料庫中。
儘管資料格式日益多樣化,現代 AI 應用程式越來越傾向於透過自然語言介面存取所有類型的資料。模型在此過程中發揮關鍵作用,將自然語言查詢轉換為與底層搜尋索引或資料庫相容的格式。這種轉換使得與複雜資料結構的互動更加直觀和靈活。
主要概念
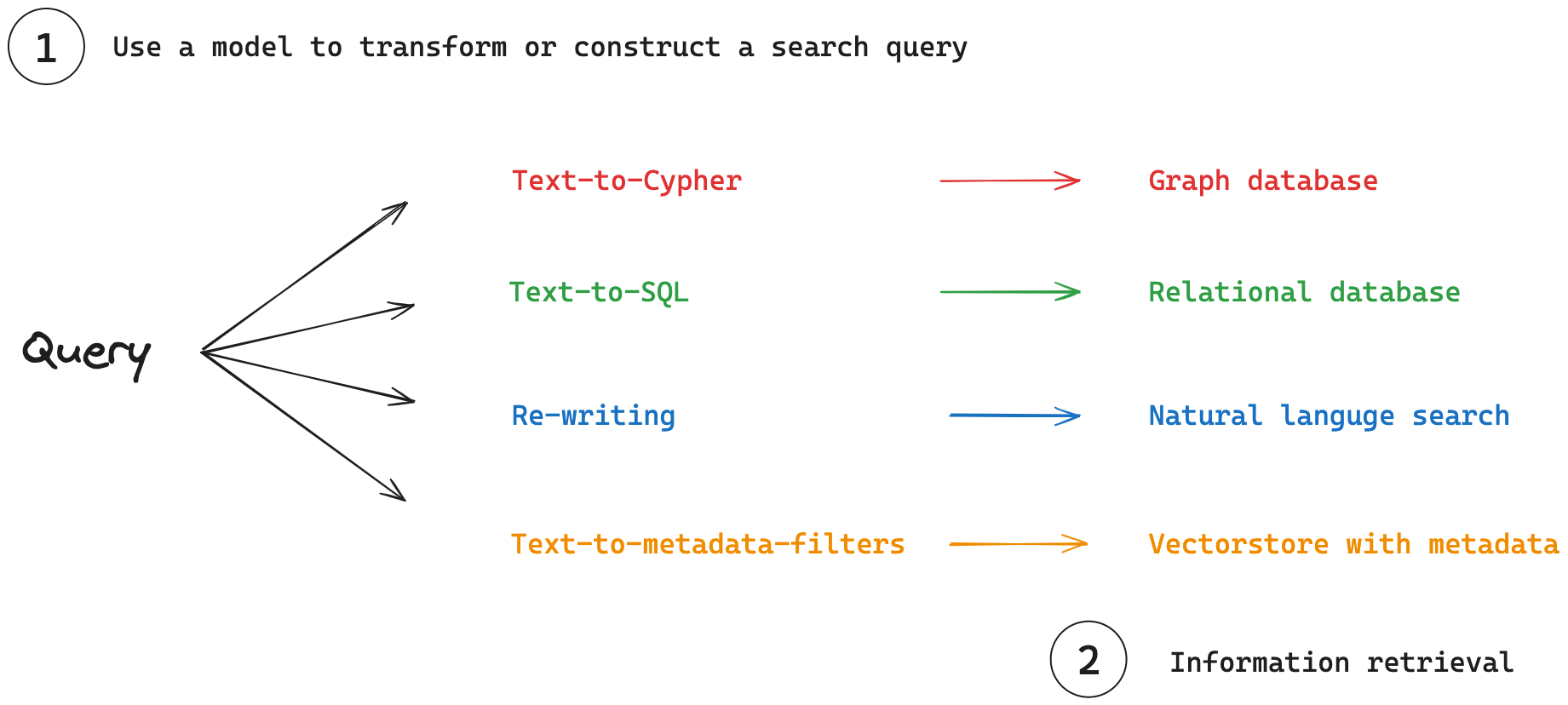
(1) 查詢分析:模型轉換或建構搜尋查詢以優化檢索的過程。
(2) 資訊檢索:搜尋查詢用於從各種檢索系統中提取資訊。
查詢分析
雖然使用者通常更喜歡使用自然語言與檢索系統互動,但這些系統可能需要特定的查詢語法或受益於某些關鍵字。查詢分析充當原始使用者輸入和優化搜尋查詢之間的橋樑。查詢分析的一些常見應用包括
- 查詢重寫:可以重寫或擴展查詢以改進語義或詞彙搜尋。
- 查詢建構:搜尋索引可能需要結構化查詢(例如,資料庫的 SQL)。
查詢分析使用模型從原始使用者輸入轉換或建構優化的搜尋查詢。
查詢重寫
理想情況下,檢索系統應處理廣泛的使用者輸入,從簡單且措辭不當的查詢到複雜、多方面的問題。為了實現這種多功能性,一種流行的方法是使用模型將原始使用者查詢轉換為更有效的搜尋查詢。這種轉換的範圍可以從簡單的關鍵字提取到複雜的查詢擴展和重新表述。以下是在非結構化資料檢索中使用模型進行查詢分析的一些主要優點
- 查詢澄清:模型可以重新措辭含糊不清或措辭不當的查詢以使其清晰。
- 語義理解:它們可以捕捉查詢背後的意圖,超越字面關鍵字匹配。
- 查詢擴展:模型可以生成相關術語或概念以擴大搜尋範圍。
- 複雜查詢處理:它們可以將多部分問題分解為更簡單的子查詢。
已經開發了各種技術來利用模型進行查詢重寫,包括
| 名稱 | 何時使用 | 描述 |
|---|---|---|
| 多重查詢 | 當您希望透過提供問題的多種措辭來確保檢索中的高召回率時。 | 使用多種措辭重寫使用者問題,檢索每個重寫問題的文件,返回所有查詢的唯一文件。 |
| 分解 | 當一個問題可以分解為更小的子問題時。 | 將一個問題分解為一組子問題/問題,這些子問題/問題可以循序解決(使用第一個問題的答案 + 檢索來回答第二個問題)或並行解決(將每個答案合併為最終答案)。 |
| 後退 | 當需要更高層次的概念理解時。 | 首先提示 LLM 提出關於更高層次概念或原則的通用後退問題,並檢索關於它們的相關事實。使用此基礎來幫助回答使用者問題。論文。 |
| HyDE | 如果您在使用原始使用者輸入檢索相關文件時遇到挑戰。 | 使用 LLM 將問題轉換為回答問題的假設文件。使用嵌入的假設文件來檢索真實文件,前提是文件-文件相似性搜尋可以產生更相關的匹配。論文。 |
作為一個例子,查詢分解可以簡單地使用提示和強制執行子問題列表的結構化輸出來完成。然後可以在下游檢索系統上循序或並行運行這些子問題。
from typing import List
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
# Define a pydantic model to enforce the output structure
class Questions(BaseModel):
questions: List[str] = Field(
description="A list of sub-questions related to the input query."
)
# Create an instance of the model and enforce the output structure
model = ChatOpenAI(model="gpt-4o", temperature=0)
structured_model = model.with_structured_output(Questions)
# Define the system prompt
system = """You are a helpful assistant that generates multiple sub-questions related to an input question. \n
The goal is to break down the input into a set of sub-problems / sub-questions that can be answers in isolation. \n"""
# Pass the question to the model
question = """What are the main components of an LLM-powered autonomous agent system?"""
questions = structured_model.invoke([SystemMessage(content=system)]+[HumanMessage(content=question)])
查詢建構
查詢分析也可以側重於將自然語言查詢翻譯成專門的查詢語言或篩選器。這種翻譯對於有效地與各種儲存結構化或半結構化資料的資料庫互動至關重要。
-
結構化資料範例:對於關聯式和圖形資料庫,領域特定語言 (DSL) 用於查詢資料。
- Text-to-SQL:將自然語言轉換為 SQL,用於關聯式資料庫。
- Text-to-Cypher:將自然語言轉換為 Cypher,用於圖形資料庫。
-
半結構化資料範例:對於向量儲存,查詢可以將語義搜尋與元數據篩選結合。
- 自然語言到元數據篩選器:將使用者查詢轉換為適當的元數據篩選器。
這些方法利用模型來彌合使用者意圖和不同資料儲存系統的特定查詢需求之間的差距。以下是一些流行的技術
| 名稱 | 何時使用 | 描述 |
|---|---|---|
| 自我查詢 | 如果使用者提出的問題更適合透過根據元數據而不是與文字的相似性來提取文件來回答。 | 這使用 LLM 將使用者輸入轉換為兩件事:(1)用於語義查找的字串,(2)與之相關聯的元數據篩選器。這很有用,因為通常問題是關於文件的元數據(而不是內容本身)。 |
| Text to SQL | 如果使用者提出的問題需要儲存在關聯式資料庫中,並且可以透過 SQL 存取的資訊。 | 這使用 LLM 將使用者輸入轉換為 SQL 查詢。 |
| Text-to-Cypher | 如果使用者提出的問題需要儲存在圖形資料庫中,並且可以透過 Cypher 存取的資訊。 | 這使用 LLM 將使用者輸入轉換為 Cypher 查詢。 |
例如,以下是如何使用 SelfQueryRetriever 將自然語言查詢轉換為元數據篩選器。
metadata_field_info = schema_for_metadata
document_content_description = "Brief summary of a movie"
llm = ChatOpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm,
vectorstore,
document_content_description,
metadata_field_info,
)
- 請參閱我們關於 text-to-SQL、text-to-Cypher 和 元數據篩選器的查詢分析 的教學課程。
- 請參閱我們的部落格文章概述。
- 請參閱我們關於 查詢建構 的 RAG from Scratch 影片。
資訊檢索
常見的檢索系統
詞彙搜尋索引
許多搜尋引擎都基於將查詢中的單字與每個文件中的單字進行匹配。這種方法稱為詞彙檢索,使用通常基於詞頻的搜尋演算法。直覺很簡單:一個單字在使用者查詢和特定文件中都頻繁出現,那麼該文件可能是一個很好的匹配。
用於實現此目的的特定資料結構通常是倒排索引。這種索引包含一個單字列表,以及每個單字到它在各種文件中出現的位置列表的映射。使用這種資料結構,可以有效地將搜尋查詢中的單字與它們出現的文件進行匹配。BM25 和 TF-IDF 是兩種流行的詞彙搜尋演算法。
- 請參閱 BM25 檢索器整合。
- 請參閱 Elasticsearch 檢索器整合。
向量索引
向量索引是索引和儲存非結構化資料的另一種方法。有關詳細概述,請參閱我們關於向量儲存的概念指南。
簡而言之,向量儲存不是使用詞頻,而是使用嵌入模型將文件壓縮成高維向量表示。這允許使用簡單的數學運算(如餘弦相似度)對嵌入向量進行有效的相似性搜尋。
關聯式資料庫
關聯式資料庫是許多應用程式中使用的基本結構化資料儲存類型。它們將資料組織成具有預定義綱要的表格,其中每個表格代表一個實體或關係。資料儲存在行(記錄)和列(屬性)中,允許透過 SQL(結構化查詢語言)進行有效的查詢和操作。關聯式資料庫擅長維護資料完整性、支援複雜查詢以及處理不同資料實體之間的關係。
- 請參閱我們關於使用 SQL 資料庫的教學課程。
- 請參閱我們的SQL 資料庫工具組。
圖形資料庫
圖形資料庫是一種專門設計用於儲存和管理高度互連資料的資料庫類型。與傳統關聯式資料庫不同,圖形資料庫使用由節點(實體)、邊(關係)和屬性組成的靈活結構。這種結構允許有效地表示和查詢複雜的、互連的資料。圖形資料庫以圖形結構儲存資料,包括節點、邊和屬性。它們特別適用於儲存和查詢資料點之間複雜的關係,例如社交網路、供應鏈管理、欺詐檢測和推薦服務
- 請參閱我們關於使用圖形資料庫的教學課程。
- 請參閱我們的圖形資料庫整合列表。
- 請參閱 Neo4j 的 LangChain 入門套件。
檢索器
LangChain 透過檢索器概念,為與各種檢索系統互動提供統一的介面。介面很簡單明瞭
- 輸入:查詢(字串)
- 輸出:文件列表(標準化的 LangChain Document 物件)
您可以使用前面提到的任何檢索系統建立檢索器。我們討論的查詢分析技術在這裡特別有用,因為它們為通常需要結構化查詢語言的資料庫啟用自然語言介面。例如,您可以使用 text-to-SQL 轉換為 SQL 資料庫建立檢索器。這允許將自然語言查詢(字串)在幕後轉換為 SQL 查詢。無論底層檢索系統是什麼,LangChain 中的所有檢索器都共用一個通用介面。您可以使用簡單的 invoke 方法來使用它們
docs = retriever.invoke(query)
- 請參閱我們的關於檢索器的概念指南。
- 請參閱我們的關於使用檢索器的操作指南。