檢索器
總覽
存在許多不同類型的檢索系統,包括向量資料庫、圖形資料庫和關聯式資料庫。隨著大型語言模型的普及,檢索系統已成為 AI 應用程式的重要組成部分(例如,RAG)。由於其重要性和可變性,LangChain 為與不同類型的檢索系統互動提供了統一的介面。LangChain 的檢索器介面非常簡單
- 輸入:查詢(字串)
- 輸出:文件清單(標準化的 LangChain Document 物件)
重點概念
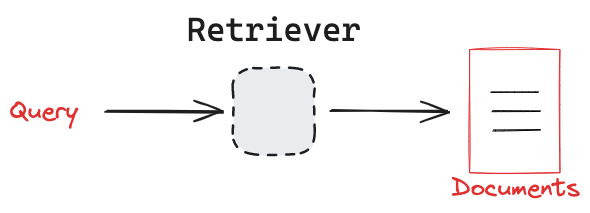
所有檢索器都實作了一個簡單的介面,用於使用自然語言查詢檢索文件。
介面
檢索器的唯一要求是能夠接受查詢並傳回文件。特別是,LangChain 的檢索器類別僅要求實作 _get_relevant_documents 方法,該方法接受 query: str 並傳回與查詢最相關的 Document 物件清單。用於取得相關文件的底層邏輯由檢索器指定,並且可以是對於應用程式最有用的任何邏輯。
LangChain 檢索器是一個可執行物件,這是一個用於 LangChain 元件的標準介面。這表示它有一些通用方法,包括 invoke,用於與其互動。檢索器可以使用查詢來調用
docs = retriever.invoke(query)
檢索器傳回 Document 物件的清單,這些物件具有兩個屬性
page_content:此文件的內容。目前是字串。metadata:與此文件相關聯的任意中繼資料(例如,文件 ID、檔案名稱、來源等)。
- 請參閱我們關於建構您自己的自訂檢索器的操作指南。
常見類型
儘管檢索器介面具有彈性,但仍經常使用一些常見類型的檢索系統。
搜尋 API
重要的是要注意,檢索器實際上不需要儲存文件。例如,我們可以在搜尋 API 之上建構檢索器,這些 API 僅傳回搜尋結果!請參閱我們與 Amazon Kendra 或 Wikipedia Search 的檢索器整合。
關聯式或圖形資料庫
檢索器可以建構在關聯式或圖形資料庫之上。在這些情況下,使用 查詢分析 技術從自然語言建構結構化查詢至關重要。例如,您可以使用文字轉 SQL 轉換為 SQL 資料庫建構檢索器。這允許將自然語言查詢(字串)檢索器在幕後轉換為 SQL 查詢。
詞彙搜尋
正如我們在 檢索 的概念回顧中所討論的,許多搜尋引擎都基於將查詢中的單字與每個文件中的單字進行比對。BM25 和 TF-IDF 是兩種熱門的詞彙搜尋演算法。LangChain 具有適用於許多熱門詞彙搜尋演算法/引擎的檢索器。
- 請參閱 BM25 檢索器整合。
- 請參閱 TF-IDF 檢索器整合。
- 請參閱 Elasticsearch 檢索器整合。
向量資料庫
向量資料庫是一種強大而有效的方式,用於索引和檢索非結構化資料。向量資料庫可以透過呼叫 as_retriever() 方法用作檢索器。
vectorstore = MyVectorStore()
retriever = vectorstore.as_retriever()
進階檢索模式
集成
由於檢索器介面非常簡單,只需傳回給定搜尋查詢的 Document 物件清單,因此可以使用集成來組合多個檢索器。當您有多個擅長尋找不同類型相關文件的檢索器時,這特別有用。可以輕鬆建立一個集成檢索器,將多個檢索器與線性加權分數組合在一起
# Initialize the ensemble retriever
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_store_retriever], weights=[0.5, 0.5]
)
在集成時,我們如何組合來自多個檢索器的搜尋結果?這激發了重新排序的概念,該概念採用多個檢索器的輸出,並使用更複雜的演算法(例如 Reciprocal Rank Fusion (RRF))將它們組合在一起。
原始文件保留
許多檢索器利用某種索引來使文件易於搜尋。索引過程可能包括轉換步驟(例如,向量資料庫通常使用文件分割)。無論使用何種轉換,保留轉換後的文件與原始文件之間的連結都非常有用,使檢索器能夠傳回原始文件。
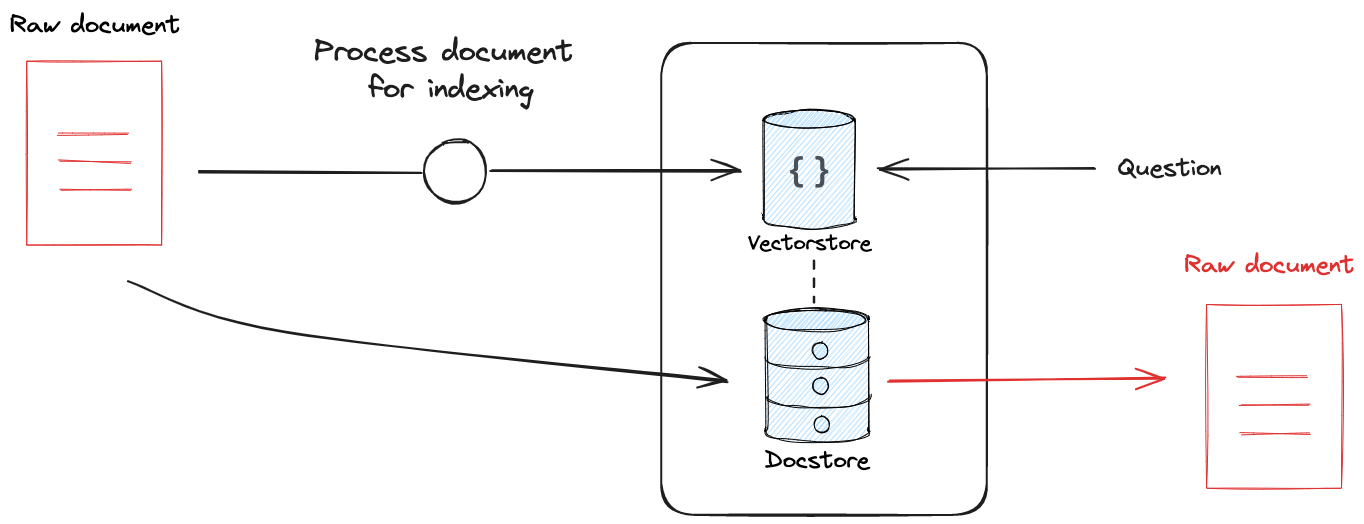
這在 AI 應用程式中特別有用,因為它可以確保模型不會遺失文件情境。例如,您可以使用小區塊大小來索引向量資料庫中的文件。如果您僅傳回區塊作為檢索結果,則模型將遺失區塊的原始文件情境。
LangChain 有兩個不同的檢索器可用於解決此挑戰。多向量檢索器允許使用者使用任何文件轉換(例如,使用 LLM 撰寫文件摘要)進行索引,同時保留與來源文件的連結。ParentDocument 檢索器連結來自文字分割器轉換的文件區塊以進行索引,同時保留與來源文件的連結。
| 名稱 | 索引類型 | 使用 LLM | 何時使用 | 描述 |
|---|---|---|---|---|
| ParentDocument | 向量資料庫 + 文件儲存區 | 否 | 如果您的頁面有許多較小的不同資訊片段,這些片段最好單獨索引,但最好一起檢索。 | 這涉及為每個文件索引多個區塊。然後,您找到在嵌入空間中最相似的區塊,但您檢索整個父文件並傳回它(而不是個別區塊)。 |
| 多向量 | 向量資料庫 + 文件儲存區 | 有時在索引期間 | 如果您能夠從文件中提取您認為比文字本身更相關的資訊進行索引。 | 這涉及為每個文件建立多個向量。每個向量可以透過多種方式建立 - 範例包括文字摘要和假設性問題。 |