令牌
現代大型語言模型 (LLM) 通常基於轉換器架構,該架構處理稱為令牌的單元序列。令牌是模型用來分解輸入和產生輸出的基本元素。在本節中,我們將討論什麼是令牌以及語言模型如何使用它們。
什麼是令牌?
令牌是語言模型讀取、處理和產生的基本單元。這些單元可能因模型提供者如何定義它們而異,但一般而言,它們可以代表
- 整個單字(例如,「apple」),
- 單字的一部分(例如,「app」),
- 或其他語言成分,例如標點符號或空格。
模型標記輸入的方式取決於其令牌化演算法,該演算法將輸入轉換為令牌。同樣地,模型的輸出以令牌流的形式出現,然後將其解碼回人類可讀的文本。
令牌在語言模型中如何運作
語言模型使用令牌的原因與它們如何理解和預測語言有關。語言模型不是直接處理字元或整個句子,而是專注於令牌,令牌代表有意義的語言單元。以下是流程的運作方式
-
輸入令牌化:當您向模型提供提示(例如,「LangChain 很酷!」)時,令牌化演算法會將文本拆分為令牌。例如,句子可以被令牌化為類似
["Lang", "Chain", " is", " cool", "!"]的部分。請注意,令牌邊界並不總是與單字邊界對齊。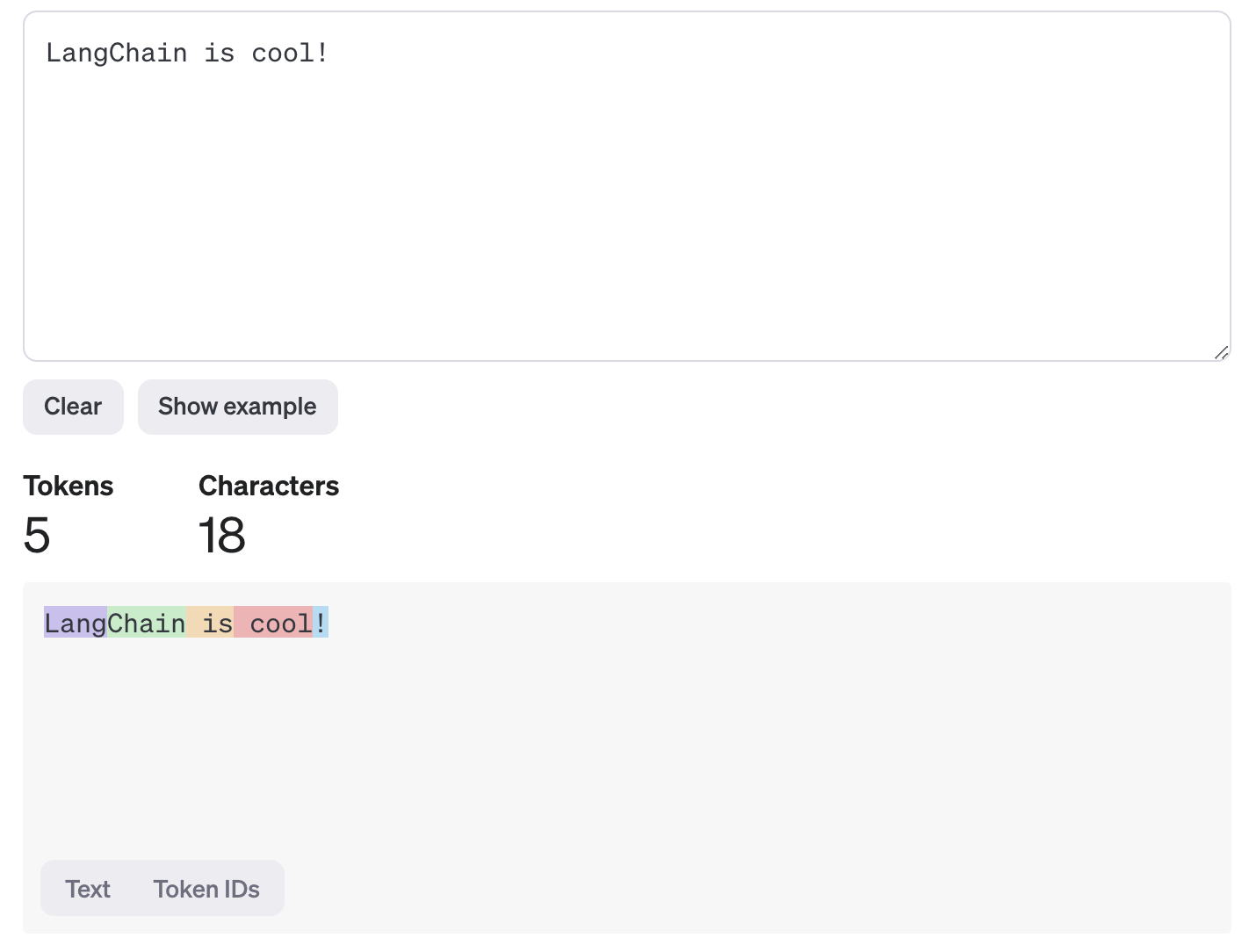
-
處理:這些模型背後的轉換器架構依序處理令牌,以預測句子中的下一個令牌。它透過分析令牌之間的關係來做到這一點,從輸入中捕捉上下文和意義。
-
輸出產生:模型逐一產生新的令牌。然後將這些輸出令牌解碼回人類可讀的文本。
使用令牌而不是原始字元可讓模型專注於語言上有意義的單元,這有助於它更有效地捕捉語法、結構和上下文。
令牌不一定是文本
雖然令牌最常用於表示文本,但它們不一定僅限於文本資料。令牌也可以作為多模態資料的抽象表示,例如
- 圖片,
- 音訊,
- 影片,
- 和其他類型的資料。
在撰寫本文時,實際上沒有模型支援多模態輸出,只有少數模型可以處理多模態輸入(例如,文本與圖片或音訊的組合)。但是,隨著 AI 的不斷進步,我們預期多模態將變得更加普遍。這將使模型能夠處理和產生更廣泛的媒體,顯著擴展令牌可以代表的範圍以及模型如何與不同類型的資料互動。
原則上,任何可以表示為令牌序列的事物都可以用類似的方式建模。例如,DNA 序列(由一系列核苷酸 (A、T、C、G) 組成)可以被令牌化和建模,以捕捉模式、進行預測或產生序列。這種靈活性使基於轉換器的模型能夠處理不同類型的循序資料,進一步擴展它們在各個領域的潛在應用,包括生物資訊學、訊號處理和其他涉及結構化或非結構化序列的領域。
請參閱多模態章節,以取得有關多模態輸入和輸出的更多資訊。
為何不使用字元?
使用令牌而不是個別字元使模型更有效率,並且更擅長理解上下文和語法。令牌代表有意義的單元,例如整個單字或單字的一部分,使模型能夠比處理原始字元更有效地捕捉語言結構。令牌級處理也減少了模型必須處理的單元數量,從而加快了計算速度。
相比之下,字元級處理將需要處理更大的輸入序列,這使得模型更難學習關係和上下文。令牌使模型能夠專注於語言意義,使其在產生回應時更準確和有效率。
令牌如何對應到文本
請參閱 OpenAI 的這篇文章,以取得有關如何計算令牌以及它們如何對應到文本的更多詳細資訊。
根據 OpenAI 的文章,英文文本的近似令牌計數如下
- 1 個令牌 ~= 4 個英文字元
- 1 個令牌 ~= ¾ 個單字
- 100 個令牌 ~= 75 個單字