向量儲存
為了簡潔起見,此概念概述著重於基於文本的索引和檢索。然而,嵌入模型可以是多模態的,並且向量儲存可以用於儲存和檢索文本以外的各種資料類型。
概述
向量儲存是專門的資料儲存庫,能夠根據向量表示來索引和檢索資訊。
這些向量稱為嵌入,捕捉了已嵌入資料的語義。
向量儲存經常被用於搜尋非結構化資料,例如文本、圖像和音訊,以根據語義相似性而非精確的關鍵字匹配來檢索相關資訊。
整合
LangChain 具有大量的向量儲存整合,允許使用者輕鬆地在不同的向量儲存實作之間切換。
介面
LangChain 提供了用於向量儲存的標準介面,允許使用者輕鬆地在不同的向量儲存實作之間切換。
該介面包含用於在向量儲存中寫入、刪除和搜尋文件的基本方法。
主要的幾種方法是
add_documents:將文本列表新增到向量儲存。delete:從向量儲存中刪除文件列表。similarity_search:搜尋與給定查詢相似的文件。
初始化
LangChain 中的大多數向量在初始化向量儲存時,都接受嵌入模型作為參數。
我們將使用 LangChain 的 InMemoryVectorStore 實作來說明 API。
from langchain_core.vectorstores import InMemoryVectorStore
# Initialize with an embedding model
vector_store = InMemoryVectorStore(embedding=SomeEmbeddingModel())
新增文件
要新增文件,請使用 add_documents 方法。
此 API 適用於 Document 物件的列表。Document 物件都具有 page_content 和 metadata 屬性,使其成為儲存非結構化文本和相關元數據的通用方式。
from langchain_core.documents import Document
document_1 = Document(
page_content="I had chocalate chip pancakes and scrambled eggs for breakfast this morning.",
metadata={"source": "tweet"},
)
document_2 = Document(
page_content="The weather forecast for tomorrow is cloudy and overcast, with a high of 62 degrees.",
metadata={"source": "news"},
)
documents = [document_1, document_2]
vector_store.add_documents(documents=documents)
您通常應該為新增到向量儲存的文件提供 ID,以便您可以更新現有文件,而不是多次新增相同的文件。
vector_store.add_documents(documents=documents, ids=["doc1", "doc2"])
刪除
要刪除文件,請使用 delete 方法,該方法接受要刪除的文件 ID 列表。
vector_store.delete(ids=["doc1"])
搜尋
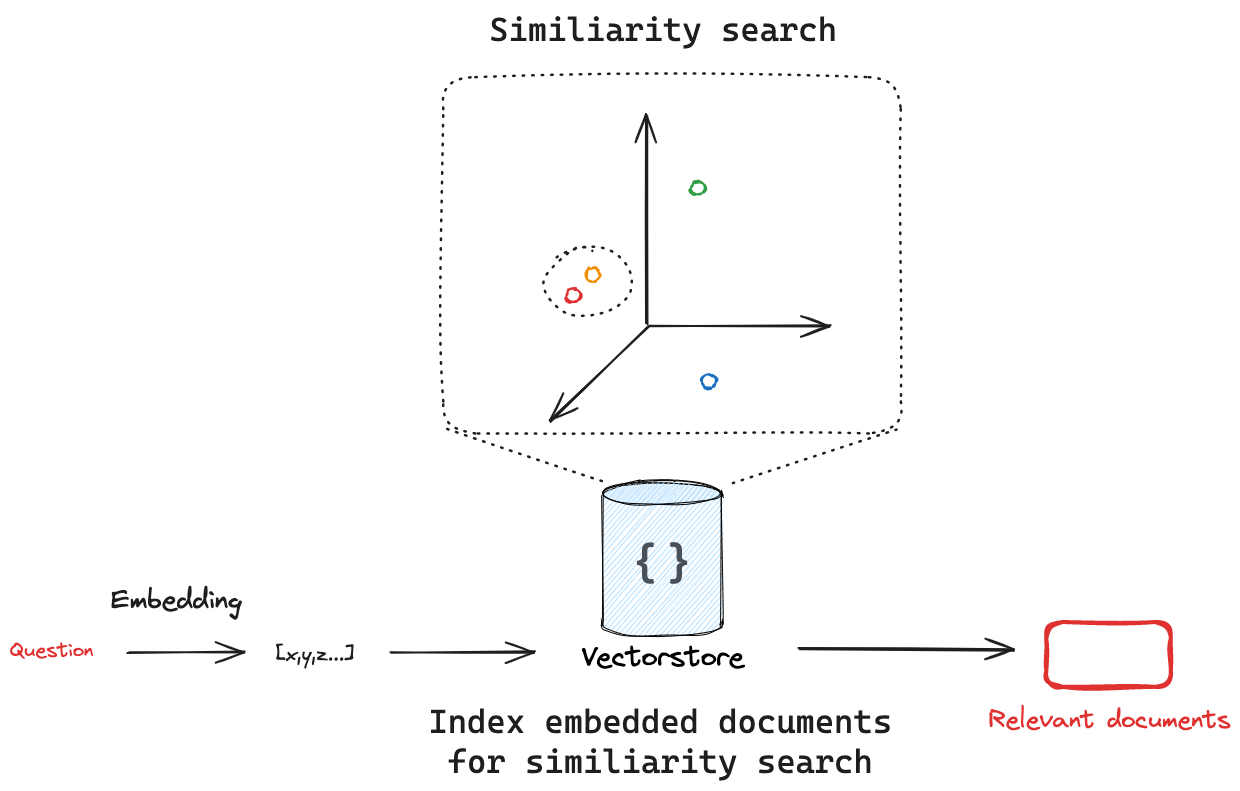
向量儲存會嵌入並儲存新增的文件。如果我們傳入查詢,向量儲存將嵌入查詢,對嵌入的文件執行相似性搜尋,並返回最相似的文件。這涵蓋了兩個重要的概念:首先,需要有一種方法來衡量查詢與任何嵌入文件之間的相似性。其次,需要有一種演算法來有效地對所有嵌入文件執行此相似性搜尋。
相似性指標
嵌入向量的一個關鍵優勢是可以使用許多簡單的數學運算來比較它們
- 餘弦相似度:測量兩個向量之間角度的餘弦值。
- 歐幾里得距離:測量兩點之間的直線距離。
- 點積:測量一個向量在另一個向量上的投影。
相似性指標的選擇有時可以在初始化向量儲存時選擇。請參閱您正在使用的特定向量儲存的文檔,以查看支援哪些相似性指標。
相似性搜尋
給定一個相似性指標來衡量嵌入的查詢與任何嵌入文件之間的距離,我們需要一種演算法來有效地搜尋所有嵌入文件,以找到最相似的文件。有很多方法可以做到這一點。例如,許多向量儲存實作了 HNSW (Hierarchical Navigable Small World),這是一種基於圖形的索引結構,可以實現高效的相似性搜尋。無論底層使用何種搜尋演算法,LangChain 向量儲存介面都為所有整合提供了 similarity_search 方法。這將獲取搜尋查詢,建立嵌入,找到相似的文件,並將它們作為 Document 列表返回。
query = "my query"
docs = vectorstore.similarity_search(query)
許多向量儲存支援使用 similarity_search 方法傳遞搜尋參數。請參閱您正在使用的特定向量儲存的文檔,以查看支援哪些參數。例如,Pinecone 提供了幾個重要的通用概念參數:許多向量儲存支援 k,它控制要返回的文件數量,以及 filter,它允許按元數據篩選文件。
query (str) – 要查找與之相似的文件的文本。k (int) – 要返回的文件數量。預設為 4。filter (dict | None) – 用於篩選元數據的參數字典。
元數據篩選
雖然向量儲存實作了一種搜尋演算法,可以有效地搜尋所有嵌入文件以找到最相似的文件,但許多向量儲存也支援按元數據進行篩選。元數據篩選有助於通過應用特定條件來縮小搜尋範圍,例如從特定來源或日期範圍檢索文件。這兩個概念可以很好地協同工作
- 語義搜尋:直接查詢非結構化資料,通常透過嵌入或關鍵字相似性。
- 元數據搜尋:將結構化查詢應用於元數據,篩選特定文件。
向量儲存對元數據篩選的支援通常取決於底層向量儲存實作。
以下是使用 Pinecone 的範例用法,顯示我們篩選所有元數據鍵 source 值為 tweet 的文件。
vectorstore.similarity_search(
"LangChain provides abstractions to make working with LLMs easy",
k=2,
filter={"source": "tweet"},
)
- 請參閱 Pinecone 關於使用元數據篩選的文檔。
- 請參閱支援元數據篩選的 LangChain 向量儲存整合列表。
進階搜尋和檢索技術
雖然像 HNSW 這樣的演算法在許多情況下為高效的相似性搜尋提供了基礎,但可以使用其他技術來提高搜尋品質和多樣性。例如,最大邊際相關性是一種用於使搜尋結果多樣化的重新排序演算法,它在初始相似性搜尋後應用,以確保更多樣化的結果集。第二個例子,一些 向量儲存 提供了內建的 混合搜尋,以結合關鍵字和語義相似性搜尋,這結合了兩種方法的優點。目前,沒有使用 LangChain 向量儲存執行混合搜尋的統一方法,但它通常作為關鍵字參數公開,並通過 similarity_search 傳遞。有關更多詳細資訊,請參閱此關於混合搜尋的操作指南。
| 名稱 | 何時使用 | 描述 |
|---|---|---|
| 混合搜尋 | 當結合基於關鍵字和語義相似性時。 | 混合搜尋結合了關鍵字和語義相似性,結合了兩種方法的優點。論文。 |
| 最大邊際相關性 (MMR) | 當需要使搜尋結果多樣化時。 | MMR 嘗試使搜尋結果多樣化,以避免返回相似和冗餘的文件。 |