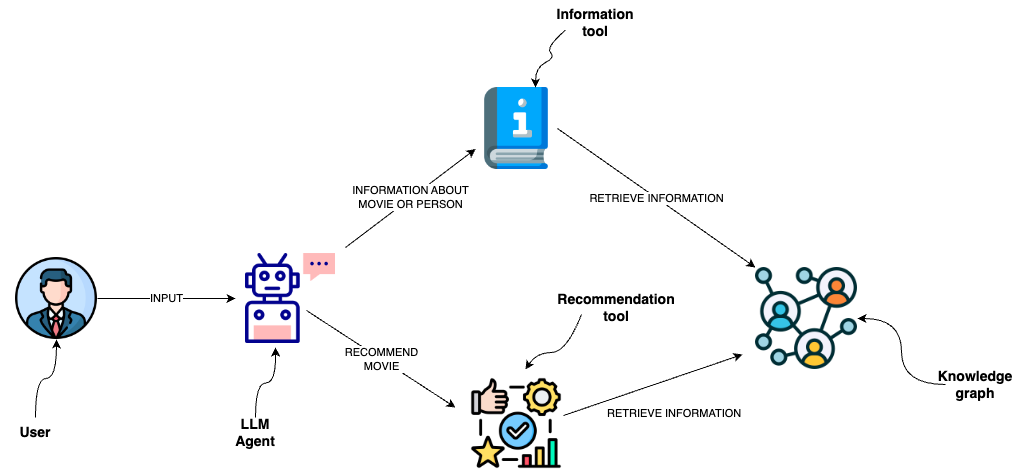
如何為圖形資料庫新增語意層
您可以使用資料庫查詢從圖形資料庫(如 Neo4j)檢索資訊。一種選擇是使用 LLM 生成 Cypher 語句。雖然這種選擇提供了極佳的彈性,但該解決方案可能很脆弱,並且無法持續產生精確的 Cypher 語句。我們可以實作 Cypher 範本作為語意層中的工具,供 LLM 代理程式互動,而不是生成 Cypher 語句。
設定
首先,取得所需的套件並設定環境變數
%pip install --upgrade --quiet langchain langchain-neo4j langchain-openai
在本指南中,我們預設使用 OpenAI 模型,但您可以將其替換為您選擇的模型提供商。
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
# os.environ["LANGSMITH_API_KEY"] = getpass.getpass()
# os.environ["LANGSMITH_TRACING"] = "true"
········
接下來,我們需要定義 Neo4j 憑證。請按照這些安裝步驟設定 Neo4j 資料庫。
os.environ["NEO4J_URI"] = "bolt://127.0.0.1:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "password"
以下範例將建立與 Neo4j 資料庫的連線,並使用關於電影及其演員的範例資料填充它。
from langchain_neo4j import Neo4jGraph
graph = Neo4jGraph(refresh_schema=False)
# Import movie information
movies_query = """
LOAD CSV WITH HEADERS FROM
'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies_small.csv'
AS row
MERGE (m:Movie {id:row.movieId})
SET m.released = date(row.released),
m.title = row.title,
m.imdbRating = toFloat(row.imdbRating)
FOREACH (director in split(row.director, '|') |
MERGE (p:Person {name:trim(director)})
MERGE (p)-[:DIRECTED]->(m))
FOREACH (actor in split(row.actors, '|') |
MERGE (p:Person {name:trim(actor)})
MERGE (p)-[:ACTED_IN]->(m))
FOREACH (genre in split(row.genres, '|') |
MERGE (g:Genre {name:trim(genre)})
MERGE (m)-[:IN_GENRE]->(g))
"""
graph.query(movies_query)
[]
使用 Cypher 範本的自訂工具
語意層由暴露給 LLM 的各種工具組成,LLM 可以使用這些工具與知識圖譜互動。它們的複雜程度可能各不相同。您可以將語意層中的每個工具視為一個函數。
我們將實作的函數是檢索關於電影或其演員陣容的資訊。
description_query = """
MATCH (m:Movie|Person)
WHERE m.title CONTAINS $candidate OR m.name CONTAINS $candidate
MATCH (m)-[r:ACTED_IN|IN_GENRE]-(t)
WITH m, type(r) as type, collect(coalesce(t.name, t.title)) as names
WITH m, type+": "+reduce(s="", n IN names | s + n + ", ") as types
WITH m, collect(types) as contexts
WITH m, "type:" + labels(m)[0] + "\ntitle: "+ coalesce(m.title, m.name)
+ "\nyear: "+coalesce(m.released,"") +"\n" +
reduce(s="", c in contexts | s + substring(c, 0, size(c)-2) +"\n") as context
RETURN context LIMIT 1
"""
def get_information(entity: str) -> str:
try:
data = graph.query(description_query, params={"candidate": entity})
return data[0]["context"]
except IndexError:
return "No information was found"
您可以觀察到我們已定義用於檢索資訊的 Cypher 語句。因此,我們可以避免生成 Cypher 語句,而僅使用 LLM 代理程式來填充輸入參數。為了向 LLM 代理程式提供關於何時使用工具及其輸入參數的額外資訊,我們將該函數包裝為工具。
from typing import Optional, Type
from langchain_core.tools import BaseTool
from pydantic import BaseModel, Field
class InformationInput(BaseModel):
entity: str = Field(description="movie or a person mentioned in the question")
class InformationTool(BaseTool):
name: str = "Information"
description: str = (
"useful for when you need to answer questions about various actors or movies"
)
args_schema: Type[BaseModel] = InformationInput
def _run(
self,
entity: str,
) -> str:
"""Use the tool."""
return get_information(entity)
async def _arun(
self,
entity: str,
) -> str:
"""Use the tool asynchronously."""
return get_information(entity)
LangGraph 代理程式
我們將使用 LangGraph 實作一個簡單的 ReAct 代理程式。
代理程式由 LLM 和工具步驟組成。當我們與代理程式互動時,我們將首先呼叫 LLM 以決定是否應使用工具。然後我們將執行一個迴圈
如果代理程式表示要採取動作(即呼叫工具),我們將執行工具並將結果傳遞回代理程式。如果代理程式未要求執行工具,我們將完成(回應用戶)。
程式碼實作非常簡單。首先,我們將工具繫結到 LLM 並定義助理步驟。
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import MessagesState
llm = ChatOpenAI(model="gpt-4o")
tools = [InformationTool()]
llm_with_tools = llm.bind_tools(tools)
# System message
sys_msg = SystemMessage(
content="You are a helpful assistant tasked with finding and explaining relevant information about movies."
)
# Node
def assistant(state: MessagesState):
return {"messages": [llm_with_tools.invoke([sys_msg] + state["messages"])]}
接下來,我們定義 LangGraph 流程。
from IPython.display import Image, display
from langgraph.graph import END, START, StateGraph
from langgraph.prebuilt import ToolNode, tools_condition
# Graph
builder = StateGraph(MessagesState)
# Define nodes: these do the work
builder.add_node("assistant", assistant)
builder.add_node("tools", ToolNode(tools))
# Define edges: these determine how the control flow moves
builder.add_edge(START, "assistant")
builder.add_conditional_edges(
"assistant",
# If the latest message (result) from assistant is a tool call -> tools_condition routes to tools
# If the latest message (result) from assistant is a not a tool call -> tools_condition routes to END
tools_condition,
)
builder.add_edge("tools", "assistant")
react_graph = builder.compile()
# Show
display(Image(react_graph.get_graph(xray=True).draw_mermaid_png()))

現在,讓我們用一個範例問題測試工作流程。
input_messages = [HumanMessage(content="Who played in the Casino?")]
messages = react_graph.invoke({"messages": input_messages})
for m in messages["messages"]:
m.pretty_print()
================================[1m Human Message [0m=================================
Who played in the Casino?
==================================[1m Ai Message [0m==================================
Tool Calls:
Information (call_j4usgFStGtBM16fuguRaeoGc)
Call ID: call_j4usgFStGtBM16fuguRaeoGc
Args:
entity: Casino
=================================[1m Tool Message [0m=================================
Name: Information
type:Movie
title: Casino
year: 1995-11-22
ACTED_IN: Robert De Niro, Joe Pesci, Sharon Stone, James Woods
IN_GENRE: Drama, Crime
==================================[1m Ai Message [0m==================================
The movie "Casino," released in 1995, features the following actors:
- Robert De Niro
- Joe Pesci
- Sharon Stone
- James Woods
The film is in the Drama and Crime genres.