在本機端執行模型
使用案例
諸如 llama.cpp、Ollama、GPT4All、llamafile 等專案的普及,突顯了在本機端(您自己的裝置上)執行 LLM 的需求。
這至少有兩個重要的優點
隱私:您的資料不會發送給第三方,也不受商業服務的服務條款約束成本:沒有推論費用,這對於 token 密集型應用程式(例如,長時間運行的模擬、摘要)非常重要
概述
在本機端運行 LLM 需要一些東西
開源 LLM:可以自由修改和共享的開源 LLM推論:在您的裝置上以可接受的延遲運行此 LLM 的能力
開源 LLM
使用者現在可以存取快速增長的 開源 LLM 集。
這些 LLM 可以在至少兩個維度上進行評估(見圖)
基礎模型:什麼是基礎模型,它是如何訓練的?微調方法:基礎模型是否經過微調?如果是,使用了什麼指令集?
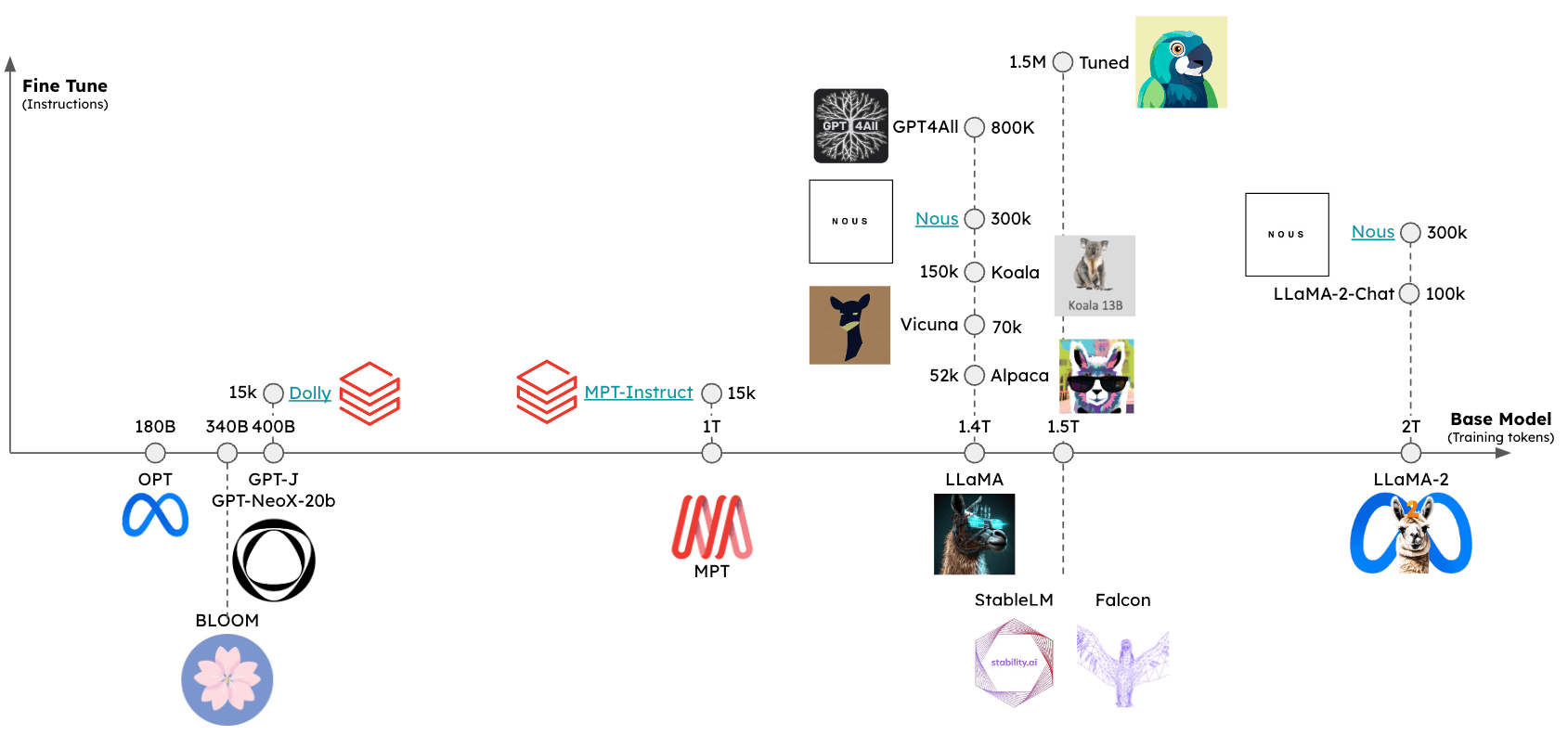
這些模型的相對效能可以使用多個排行榜進行評估,包括
推論
已經出現了一些框架來支援在各種裝置上對開源 LLM 進行推論
llama.cpp:llama 推論程式碼的 C++ 實作,具有 權重最佳化/量化gpt4all:用於推論的優化 C 後端Ollama:將模型權重和環境捆綁到一個應用程式中,該應用程式在裝置上運行並為 LLM 提供服務llamafile:將模型權重和運行模型所需的一切捆綁到一個單一檔案中,讓您可以從此檔案在本機端運行 LLM,而無需任何額外的安裝步驟
一般來說,這些框架會做幾件事
量化:減少原始模型權重的記憶體佔用用於推論的有效實作:支援在消費級硬體(例如,CPU 或筆記型電腦 GPU)上進行推論
特別是,請參閱這篇關於量化重要性的優秀文章。
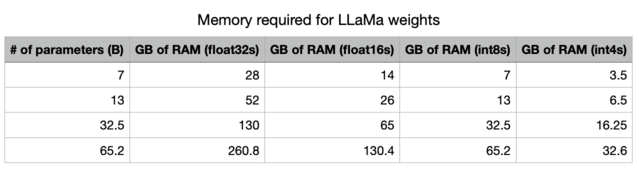
透過降低精確度,我們大幅減少了將 LLM 儲存在記憶體中所需的記憶體。
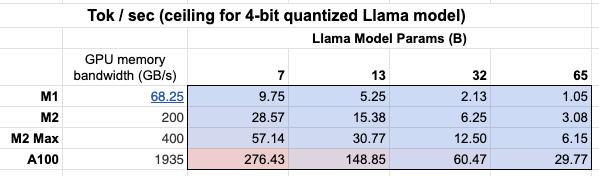
此外,我們可以了解 GPU 記憶體頻寬的重要性 表格!
Mac M2 Max 的推論速度比 M1 快 5-6 倍,因為 GPU 記憶體頻寬更大。
格式化提示
某些提供者具有 聊天模型 包裝器,可負責為您正在使用的特定本機模型格式化輸入提示。但是,如果您使用 文本輸入/文本輸出 LLM 包裝器提示本機模型,則可能需要使用針對您的特定模型量身定制的提示。
這可能需要包含特殊 token。這是 LLaMA 2 的範例。
快速入門
Ollama 是一種在 macOS 上輕鬆運行推論的方法。
此處的說明提供了詳細資訊,我們將其總結如下
%pip install -qU langchain_ollama
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="llama3.1:8b")
llm.invoke("The first man on the moon was ...")
'...Neil Armstrong!\n\nOn July 20, 1969, Neil Armstrong became the first person to set foot on the lunar surface, famously declaring "That\'s one small step for man, one giant leap for mankind" as he stepped off the lunar module Eagle onto the Moon\'s surface.\n\nWould you like to know more about the Apollo 11 mission or Neil Armstrong\'s achievements?'
在 token 生成時串流它們
for chunk in llm.stream("The first man on the moon was ..."):
print(chunk, end="|", flush=True)
...|
``````output
Neil| Armstrong|,| an| American| astronaut|.| He| stepped| out| of| the| lunar| module| Eagle| and| onto| the| surface| of| the| Moon| on| July| |20|,| |196|9|,| famously| declaring|:| "|That|'s| one| small| step| for| man|,| one| giant| leap| for| mankind|."||
Ollama 還包括一個聊天模型包裝器,用於處理格式化對話輪次
from langchain_ollama import ChatOllama
chat_model = ChatOllama(model="llama3.1:8b")
chat_model.invoke("Who was the first man on the moon?")
AIMessage(content='The answer is a historic one!\n\nThe first man to walk on the Moon was Neil Armstrong, an American astronaut and commander of the Apollo 11 mission. On July 20, 1969, Armstrong stepped out of the lunar module Eagle onto the surface of the Moon, famously declaring:\n\n"That\'s one small step for man, one giant leap for mankind."\n\nArmstrong was followed by fellow astronaut Edwin "Buzz" Aldrin, who also walked on the Moon during the mission. Michael Collins remained in orbit around the Moon in the command module Columbia.\n\nNeil Armstrong passed away on August 25, 2012, but his legacy as a pioneering astronaut and engineer continues to inspire people around the world!', response_metadata={'model': 'llama3.1:8b', 'created_at': '2024-08-01T00:38:29.176717Z', 'message': {'role': 'assistant', 'content': ''}, 'done_reason': 'stop', 'done': True, 'total_duration': 10681861417, 'load_duration': 34270292, 'prompt_eval_count': 19, 'prompt_eval_duration': 6209448000, 'eval_count': 141, 'eval_duration': 4432022000}, id='run-7bed57c5-7f54-4092-912c-ae49073dcd48-0', usage_metadata={'input_tokens': 19, 'output_tokens': 141, 'total_tokens': 160})
環境
在本機端運行模型時,推論速度是一個挑戰(見上文)。
為了最大限度地減少延遲,最好在 GPU 上在本機端運行模型,許多消費級筆記型電腦都配備了 GPU,例如 Apple 裝置。
即使使用 GPU,可用的 GPU 記憶體頻寬(如上所述)也很重要。
運行 Apple 晶片 GPU
Ollama 和 llamafile 將自動利用 Apple 裝置上的 GPU。
其他框架要求使用者設定環境以利用 Apple GPU。
例如,可以將 llama.cpp python 綁定配置為透過 Metal 使用 GPU。
Metal 是 Apple 創建的圖形和計算 API,可近乎直接地存取 GPU。
特別是,確保 conda 使用您建立的正確虛擬環境 (miniforge3)。
例如,對我來說
conda activate /Users/rlm/miniforge3/envs/llama
確認上述內容後,然後
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install -U llama-cpp-python --no-cache-dir
LLM
有多種方法可以存取量化模型權重。
HuggingFace- 許多量化模型可供下載,並且可以使用llama.cpp等框架運行。您也可以從 HuggingFace 下載llamafile格式的模型。gpt4all- 模型瀏覽器提供指標排行榜以及可供下載的相關量化模型Ollama- 可以透過pull直接存取多個模型
Ollama
使用 Ollama,透過 ollama pull <模型系列>:<標籤> 獲取模型
- 例如,對於 Llama 2 7b:
ollama pull llama2將下載模型的最基本版本(例如,最小的參數數量和 4 位元量化) - 我們也可以從模型清單中指定特定版本,例如,
ollama pull llama2:13b - 請參閱 API 參考頁面上的完整參數集
llm = OllamaLLM(model="llama2:13b")
llm.invoke("The first man on the moon was ... think step by step")
' Sure! Here\'s the answer, broken down step by step:\n\nThe first man on the moon was... Neil Armstrong.\n\nHere\'s how I arrived at that answer:\n\n1. The first manned mission to land on the moon was Apollo 11.\n2. The mission included three astronauts: Neil Armstrong, Edwin "Buzz" Aldrin, and Michael Collins.\n3. Neil Armstrong was the mission commander and the first person to set foot on the moon.\n4. On July 20, 1969, Armstrong stepped out of the lunar module Eagle and onto the moon\'s surface, famously declaring "That\'s one small step for man, one giant leap for mankind."\n\nSo, the first man on the moon was Neil Armstrong!'
Llama.cpp
Llama.cpp 與廣泛的模型集相容。
例如,下面我們使用從 HuggingFace 下載的 4 位元量化,在 llama2-13b 上運行推論。
如上所述,請參閱 API 參考以取得完整的參數集。
從 llama.cpp API 參考文件中,有幾個值得評論
n_gpu_layers:要載入到 GPU 記憶體中的層數
- 值:1
- 含義:只有模型的一層會載入到 GPU 記憶體中(1 通常就足夠了)。
n_batch:模型應平行處理的 token 數量
- 值:n_batch
- 含義:建議選擇介於 1 和 n_ctx 之間的值(在本例中設定為 2048)
n_ctx:Token 上下文視窗
- 值:2048
- 含義:模型將一次考慮 2048 個 token 的視窗
f16_kv:模型是否應對鍵/值快取使用半精度
- 值:True
- 含義:模型將使用半精度,這可以更節省記憶體;Metal 僅支援 True。
%env CMAKE_ARGS="-DLLAMA_METAL=on"
%env FORCE_CMAKE=1
%pip install --upgrade --quiet llama-cpp-python --no-cache-dirclear
from langchain_community.llms import LlamaCpp
from langchain_core.callbacks import CallbackManager, StreamingStdOutCallbackHandler
llm = LlamaCpp(
model_path="/Users/rlm/Desktop/Code/llama.cpp/models/openorca-platypus2-13b.gguf.q4_0.bin",
n_gpu_layers=1,
n_batch=512,
n_ctx=2048,
f16_kv=True,
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),
verbose=True,
)
主控台日誌將顯示以下內容,以指示 Metal 已從上述步驟正確啟用
ggml_metal_init: allocating
ggml_metal_init: using MPS
llm.invoke("The first man on the moon was ... Let's think step by step")
Llama.generate: prefix-match hit
``````output
and use logical reasoning to figure out who the first man on the moon was.
Here are some clues:
1. The first man on the moon was an American.
2. He was part of the Apollo 11 mission.
3. He stepped out of the lunar module and became the first person to set foot on the moon's surface.
4. His last name is Armstrong.
Now, let's use our reasoning skills to figure out who the first man on the moon was. Based on clue #1, we know that the first man on the moon was an American. Clue #2 tells us that he was part of the Apollo 11 mission. Clue #3 reveals that he was the first person to set foot on the moon's surface. And finally, clue #4 gives us his last name: Armstrong.
Therefore, the first man on the moon was Neil Armstrong!
``````output
llama_print_timings: load time = 9623.21 ms
llama_print_timings: sample time = 143.77 ms / 203 runs ( 0.71 ms per token, 1412.01 tokens per second)
llama_print_timings: prompt eval time = 485.94 ms / 7 tokens ( 69.42 ms per token, 14.40 tokens per second)
llama_print_timings: eval time = 6385.16 ms / 202 runs ( 31.61 ms per token, 31.64 tokens per second)
llama_print_timings: total time = 7279.28 ms
" and use logical reasoning to figure out who the first man on the moon was.\n\nHere are some clues:\n\n1. The first man on the moon was an American.\n2. He was part of the Apollo 11 mission.\n3. He stepped out of the lunar module and became the first person to set foot on the moon's surface.\n4. His last name is Armstrong.\n\nNow, let's use our reasoning skills to figure out who the first man on the moon was. Based on clue #1, we know that the first man on the moon was an American. Clue #2 tells us that he was part of the Apollo 11 mission. Clue #3 reveals that he was the first person to set foot on the moon's surface. And finally, clue #4 gives us his last name: Armstrong.\nTherefore, the first man on the moon was Neil Armstrong!"
GPT4All
我們可以使用從 GPT4All 模型瀏覽器下載的模型權重。
與上面顯示的內容類似,我們可以運行推論並使用 API 參考設定感興趣的參數。
%pip install gpt4all
from langchain_community.llms import GPT4All
llm = GPT4All(
model="/Users/rlm/Desktop/Code/gpt4all/models/nous-hermes-13b.ggmlv3.q4_0.bin"
)
llm.invoke("The first man on the moon was ... Let's think step by step")
".\n1) The United States decides to send a manned mission to the moon.2) They choose their best astronauts and train them for this specific mission.3) They build a spacecraft that can take humans to the moon, called the Lunar Module (LM).4) They also create a larger spacecraft, called the Saturn V rocket, which will launch both the LM and the Command Service Module (CSM), which will carry the astronauts into orbit.5) The mission is planned down to the smallest detail: from the trajectory of the rockets to the exact movements of the astronauts during their moon landing.6) On July 16, 1969, the Saturn V rocket launches from Kennedy Space Center in Florida, carrying the Apollo 11 mission crew into space.7) After one and a half orbits around the Earth, the LM separates from the CSM and begins its descent to the moon's surface.8) On July 20, 1969, at 2:56 pm EDT (GMT-4), Neil Armstrong becomes the first man on the moon. He speaks these"
llamafile
在本機端運行 LLM 最簡單的方法之一是使用 llamafile。您只需要做的是
- 從 HuggingFace 下載 llamafile
- 使檔案可執行
- 運行檔案
llamafile 將模型權重和 特別編譯的 llama.cpp 版本捆綁到一個單一檔案中,該檔案可以在大多數電腦上運行,而無需任何額外的依賴項。它們還附帶一個嵌入式推論伺服器,該伺服器提供一個 API,用於與您的模型互動。
這是一個簡單的 bash 腳本,顯示了所有 3 個設定步驟
# Download a llamafile from HuggingFace
wget https://huggingface.co/jartine/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
# Make the file executable. On Windows, instead just rename the file to end in ".exe".
chmod +x TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
# Start the model server. Listens at https://127.0.0.1:8080 by default.
./TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile --server --nobrowser
在您運行上述設定步驟後,您可以使用 LangChain 與您的模型互動
from langchain_community.llms.llamafile import Llamafile
llm = Llamafile()
llm.invoke("The first man on the moon was ... Let's think step by step.")
"\nFirstly, let's imagine the scene where Neil Armstrong stepped onto the moon. This happened in 1969. The first man on the moon was Neil Armstrong. We already know that.\n2nd, let's take a step back. Neil Armstrong didn't have any special powers. He had to land his spacecraft safely on the moon without injuring anyone or causing any damage. If he failed to do this, he would have been killed along with all those people who were on board the spacecraft.\n3rd, let's imagine that Neil Armstrong successfully landed his spacecraft on the moon and made it back to Earth safely. The next step was for him to be hailed as a hero by his people back home. It took years before Neil Armstrong became an American hero.\n4th, let's take another step back. Let's imagine that Neil Armstrong wasn't hailed as a hero, and instead, he was just forgotten. This happened in the 1970s. Neil Armstrong wasn't recognized for his remarkable achievement on the moon until after he died.\n5th, let's take another step back. Let's imagine that Neil Armstrong didn't die in the 1970s and instead, lived to be a hundred years old. This happened in 2036. In the year 2036, Neil Armstrong would have been a centenarian.\nNow, let's think about the present. Neil Armstrong is still alive. He turned 95 years old on July 20th, 2018. If he were to die now, his achievement of becoming the first human being to set foot on the moon would remain an unforgettable moment in history.\nI hope this helps you understand the significance and importance of Neil Armstrong's achievement on the moon!"
提示
某些 LLM 將受益於特定的提示。
例如,LLaMA 將使用特殊 token。
我們可以使用 ConditionalPromptSelector 根據模型類型設定提示。
# Set our LLM
llm = LlamaCpp(
model_path="/Users/rlm/Desktop/Code/llama.cpp/models/openorca-platypus2-13b.gguf.q4_0.bin",
n_gpu_layers=1,
n_batch=512,
n_ctx=2048,
f16_kv=True,
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),
verbose=True,
)
根據模型版本設定相關的提示。
from langchain.chains.prompt_selector import ConditionalPromptSelector
from langchain_core.prompts import PromptTemplate
DEFAULT_LLAMA_SEARCH_PROMPT = PromptTemplate(
input_variables=["question"],
template="""<<SYS>> \n You are an assistant tasked with improving Google search \
results. \n <</SYS>> \n\n [INST] Generate THREE Google search queries that \
are similar to this question. The output should be a numbered list of questions \
and each should have a question mark at the end: \n\n {question} [/INST]""",
)
DEFAULT_SEARCH_PROMPT = PromptTemplate(
input_variables=["question"],
template="""You are an assistant tasked with improving Google search \
results. Generate THREE Google search queries that are similar to \
this question. The output should be a numbered list of questions and each \
should have a question mark at the end: {question}""",
)
QUESTION_PROMPT_SELECTOR = ConditionalPromptSelector(
default_prompt=DEFAULT_SEARCH_PROMPT,
conditionals=[(lambda llm: isinstance(llm, LlamaCpp), DEFAULT_LLAMA_SEARCH_PROMPT)],
)
prompt = QUESTION_PROMPT_SELECTOR.get_prompt(llm)
prompt
PromptTemplate(input_variables=['question'], output_parser=None, partial_variables={}, template='<<SYS>> \n You are an assistant tasked with improving Google search results. \n <</SYS>> \n\n [INST] Generate THREE Google search queries that are similar to this question. The output should be a numbered list of questions and each should have a question mark at the end: \n\n {question} [/INST]', template_format='f-string', validate_template=True)
# Chain
chain = prompt | llm
question = "What NFL team won the Super Bowl in the year that Justin Bieber was born?"
chain.invoke({"question": question})
Sure! Here are three similar search queries with a question mark at the end:
1. Which NBA team did LeBron James lead to a championship in the year he was drafted?
2. Who won the Grammy Awards for Best New Artist and Best Female Pop Vocal Performance in the same year that Lady Gaga was born?
3. What MLB team did Babe Ruth play for when he hit 60 home runs in a single season?
``````output
llama_print_timings: load time = 14943.19 ms
llama_print_timings: sample time = 72.93 ms / 101 runs ( 0.72 ms per token, 1384.87 tokens per second)
llama_print_timings: prompt eval time = 14942.95 ms / 93 tokens ( 160.68 ms per token, 6.22 tokens per second)
llama_print_timings: eval time = 3430.85 ms / 100 runs ( 34.31 ms per token, 29.15 tokens per second)
llama_print_timings: total time = 18578.26 ms
' Sure! Here are three similar search queries with a question mark at the end:\n\n1. Which NBA team did LeBron James lead to a championship in the year he was drafted?\n2. Who won the Grammy Awards for Best New Artist and Best Female Pop Vocal Performance in the same year that Lady Gaga was born?\n3. What MLB team did Babe Ruth play for when he hit 60 home runs in a single season?'
我們也可以使用 LangChain Prompt Hub 來獲取和/或儲存模型特定的提示。
這將與您的 LangSmith API 金鑰一起使用。
例如,這裡是一個用於 RAG 的提示,其中包含 LLaMA 特定的 token。
使用案例
給定從上述模型之一建立的 llm,您可以將其用於許多使用案例。
例如,您可以使用此處示範的聊天模型實作 RAG 應用程式。
一般來說,本機 LLM 的使用案例可以由至少兩個因素驅動
隱私:使用者不想分享的私人資料(例如,日記等)成本:文本預處理(提取/標記)、摘要和代理模擬是 token 使用密集型任務
此外,這裡概述了微調,它可以利用開源 LLM。