![]()
將文本分類為標籤
標籤是指為文件標註類別,例如
- 情感
- 語言
- 風格(正式、非正式等)
- 涵蓋主題
- 政治傾向
概觀
標籤具有幾個組件
快速入門
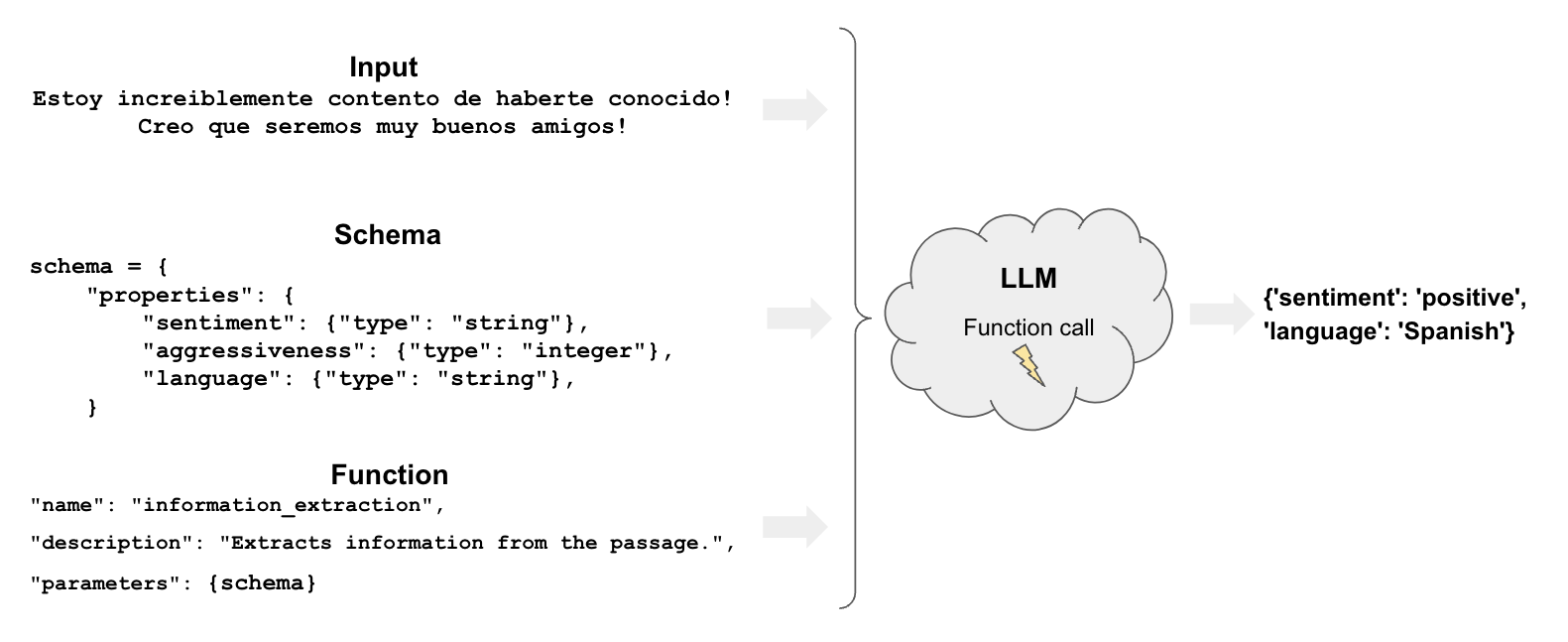
讓我們來看一個非常簡單的範例,說明如何在 LangChain 中使用 OpenAI 工具調用進行標籤。我們將使用 OpenAI 模型支援的 with_structured_output 方法。
pip install --upgrade --quiet langchain-core
我們需要載入聊天模型
選擇聊天模型
pip install -qU "langchain[openai]"
import getpass
import os
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter API key for OpenAI: ")
from langchain.chat_models import init_chat_model
llm = init_chat_model("gpt-4o-mini", model_provider="openai")
讓我們在 schema 中指定一個具有幾個屬性及其預期類型的 Pydantic 模型。
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
tagging_prompt = ChatPromptTemplate.from_template(
"""
Extract the desired information from the following passage.
Only extract the properties mentioned in the 'Classification' function.
Passage:
{input}
"""
)
class Classification(BaseModel):
sentiment: str = Field(description="The sentiment of the text")
aggressiveness: int = Field(
description="How aggressive the text is on a scale from 1 to 10"
)
language: str = Field(description="The language the text is written in")
# LLM
llm = ChatOpenAI(temperature=0, model="gpt-4o-mini").with_structured_output(
Classification
)
API 參考:ChatPromptTemplate | ChatOpenAI
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"
prompt = tagging_prompt.invoke({"input": inp})
response = llm.invoke(prompt)
response
Classification(sentiment='positive', aggressiveness=1, language='Spanish')
如果我們想要字典輸出,我們可以調用 .model_dump()
inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"
prompt = tagging_prompt.invoke({"input": inp})
response = llm.invoke(prompt)
response.model_dump()
{'sentiment': 'enojado', 'aggressiveness': 8, 'language': 'es'}
正如我們在範例中看到的,它正確地解釋了我們想要什麼。
結果會有所不同,因此我們可能會得到不同語言的情感(「正面」、「生氣」等)。
我們將在下一節中看到如何控制這些結果。
更精細的控制
仔細的 schema 定義讓我們可以更精確地控制模型的輸出。
具體來說,我們可以定義
- 每個屬性的可能值
- 描述以確保模型理解該屬性
- 要返回的必要屬性
讓我們重新宣告 Pydantic 模型,以使用列舉控制先前提到各個方面
class Classification(BaseModel):
sentiment: str = Field(..., enum=["happy", "neutral", "sad"])
aggressiveness: int = Field(
...,
description="describes how aggressive the statement is, the higher the number the more aggressive",
enum=[1, 2, 3, 4, 5],
)
language: str = Field(
..., enum=["spanish", "english", "french", "german", "italian"]
)
tagging_prompt = ChatPromptTemplate.from_template(
"""
Extract the desired information from the following passage.
Only extract the properties mentioned in the 'Classification' function.
Passage:
{input}
"""
)
llm = ChatOpenAI(temperature=0, model="gpt-4o-mini").with_structured_output(
Classification
)
現在答案將以我們期望的方式受到限制!
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"
prompt = tagging_prompt.invoke({"input": inp})
llm.invoke(prompt)
Classification(sentiment='positive', aggressiveness=1, language='Spanish')
inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"
prompt = tagging_prompt.invoke({"input": inp})
llm.invoke(prompt)
Classification(sentiment='enojado', aggressiveness=8, language='es')
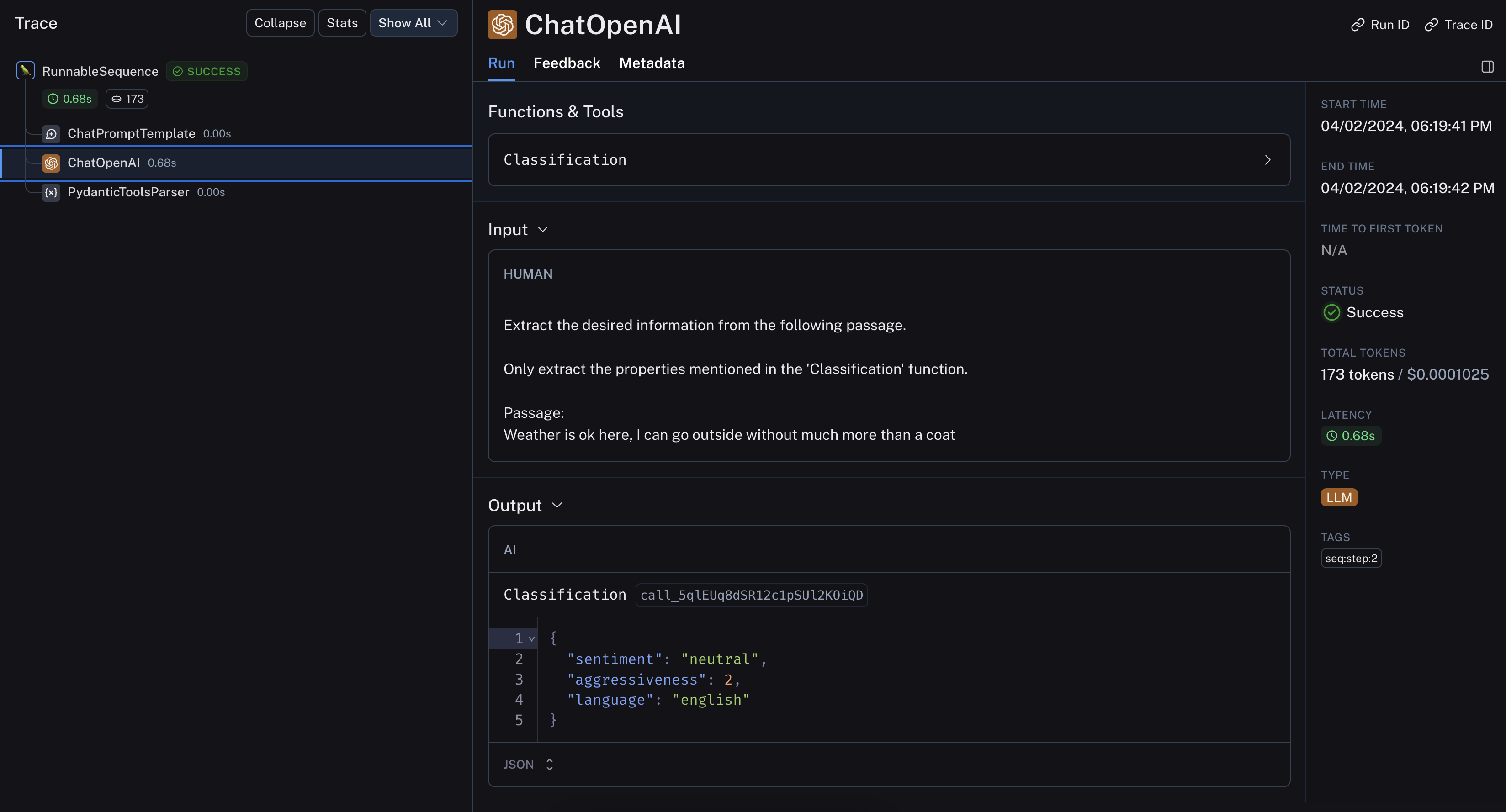
inp = "Weather is ok here, I can go outside without much more than a coat"
prompt = tagging_prompt.invoke({"input": inp})
llm.invoke(prompt)
Classification(sentiment='neutral', aggressiveness=1, language='English')
LangSmith 追蹤讓我們可以深入了解底層運作
更深入探討
- 您可以使用元數據標籤器文件轉換器,從 LangChain
Document中萃取元數據。 - 這涵蓋與標籤鏈相同基本功能,僅適用於 LangChain
Document。